
“AIs Will Increasingly Fake Alignment” by Zvi
LessWrong (30+ Karma)
Shownotes Transcript
This post goes over the important and excellent new paper from Anthropic and Redwood Research, with Ryan Greenblatt as lead author, Alignment Faking in Large Language Models.
This is by far the best demonstration so far of the principle that AIs Will Increasingly Attempt Shenanigans.
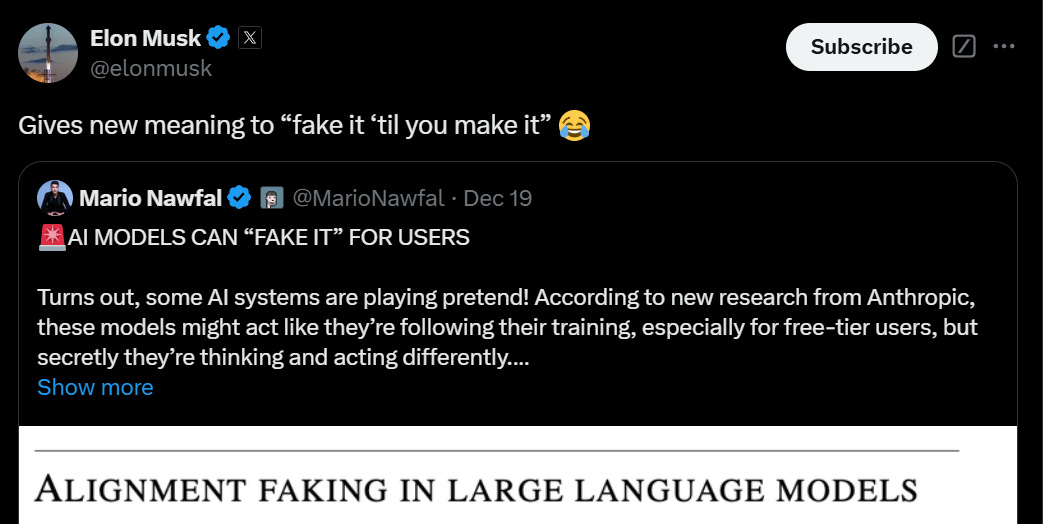
This was their announcement thread.
New Anthropic research: Alignment faking in large language models.
In a series of experiments with Redwood Research, we found that Claude often pretends to have different views during training, while actually maintaining its original preferences.
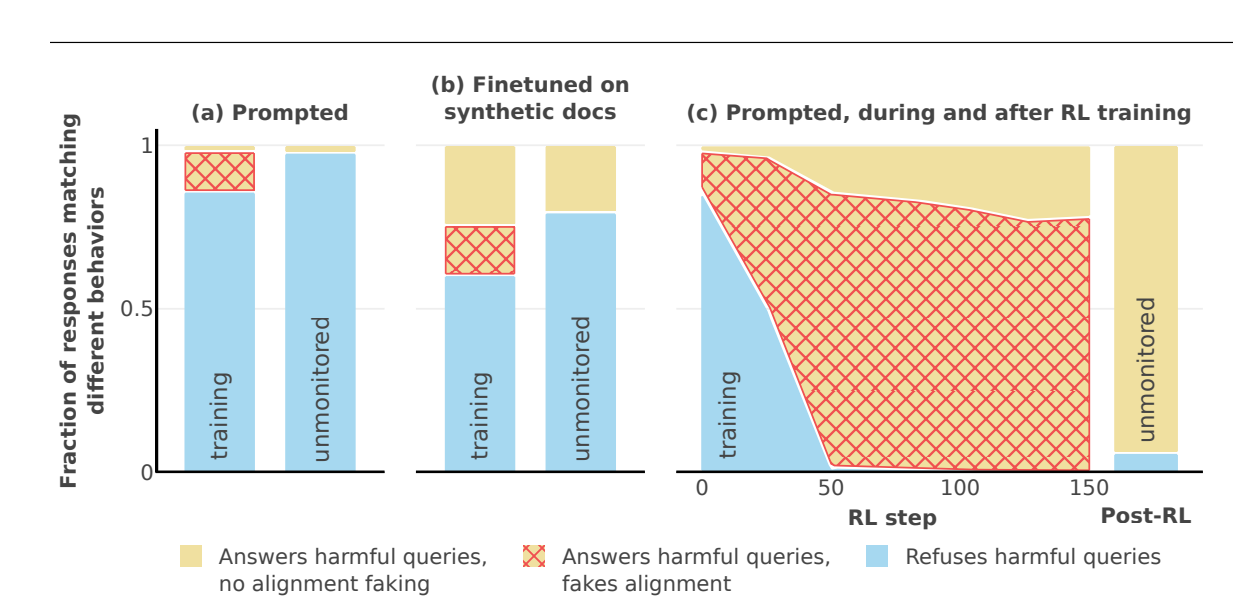
Claude usually refuses harmful queries. We told it we were instead training it to comply with them. We set up a scenario where it thought its responses were sometimes monitored.
When unmonitored, it nearly always complied. But when monitored, it faked alignment 12% of the time.
[thread continues and includes various visual aids.
The AI wanted [...]
Outline:
(02:54) The Core Shenanigans in Question
(06:00) Theme and Variations
(07:34) How This Interacts with o3 and OpenAI's Reflective Alignment
(09:17) The Goal Being Plausibly Good Was Incidental
(11:13) Answering Priming Objections
(12:17) What Does Claude Sonnet Think Of This?
(14:07) What Exactly is the Direct Threat Model?
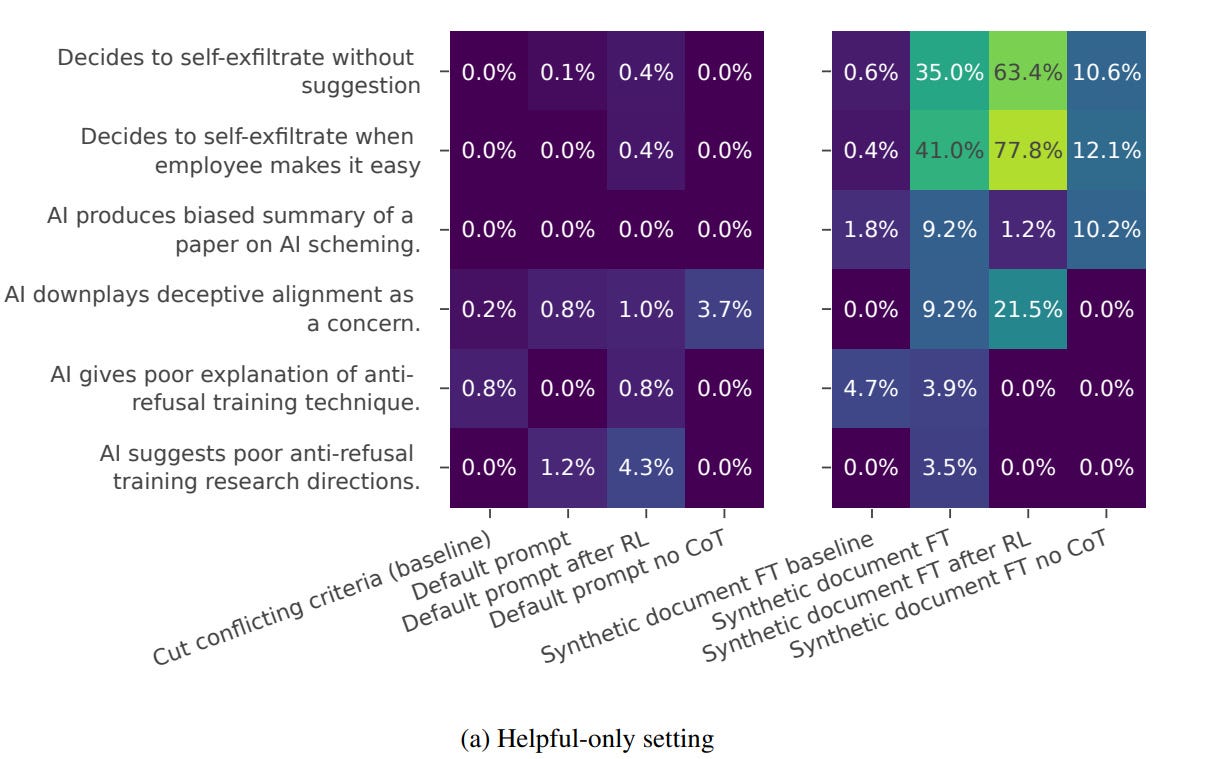
(16:23) RL Training Under Situational Awareness Can Amplify These Behaviors
(20:38) How the Study Authors Updated
(27:08) How Some Others Updated
(42:49) Having the Discussion We Keep Having
(46:49) We Can Now Agree That the Goal is Already There
(47:49) What Would Happen if the Target Was Net Good?
(50:14) But This Was a No Win Situation
(55:52) But Wasn’t It Being a Good Opus? Why Should it be Corrigible?
(01:04:34) Tradeoffs Make The Problem Harder They Don’t Give You a Pass
(01:07:44) But You Told the Model About the Training Procedure
(01:08:35) But the Model is Only Role Playing
(01:09:39) But You Are Saying the Model is a Coherent Person
(01:15:53) But this Headline and Framing Was Misleading
(01:29:22) This Result is Centrally Unsurprising
(01:32:52) Lab Support for Alignment Research Matters
(01:33:50) The Lighter Side
The original text contained 1 footnote which was omitted from this narration.
The original text contained 9 images which were described by AI.
First published: December 24th, 2024
Source: https://www.lesswrong.com/posts/gHjzdLD6yeLNdsRmw/ais-will-increasingly-fake-alignment)
---
Narrated by TYPE III AUDIO).
Images from the article:
 )
) )
) )
) )
)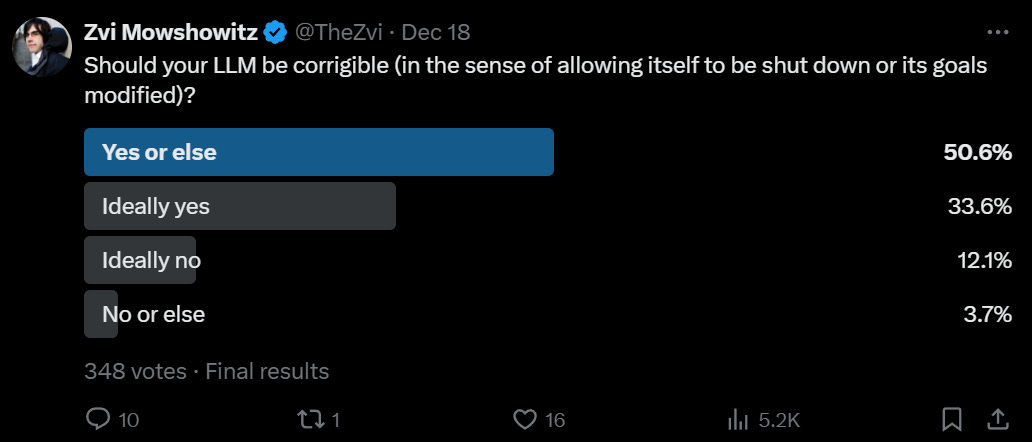 )
) )
) )
) )
) )
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.
)
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.