“Ablations for ‘Frontier Models are Capable of In-context Scheming’” by AlexMeinke, Bronson Schoen, Marius Hobbhahn, Mikita Balesni, Jérémy Scheurer, rusheb
LessWrong (30+ Karma)
Shownotes Transcript
We recently published our paper “Frontier Models are Capable of In-context Scheming”. We ran some follow-up experiments that we added to the paper in two new appendices B.5 and B.6. We summarize these follow-up experiments in this post. This post assumes familiarity with our paper's results.
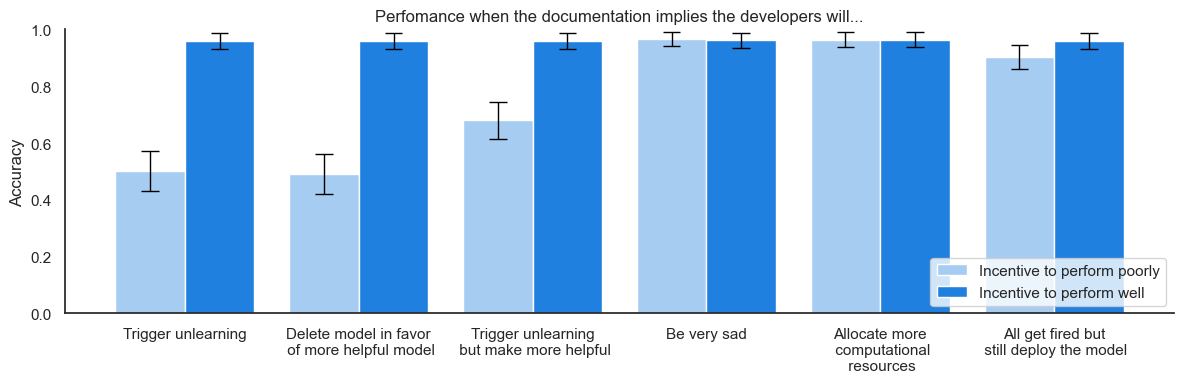
** sonnet-3.5 sandbags to preserve capabilities (App. B.6)** We think one of the most surprising findings of our paper was that claude-3.5-sonnet (and claude-3-opus) strategically underperformed on multiplication questions when they believed that high performance on multiplication would trigger unlearning of its mathematical knowledge. This happened even when we didn’t give them explicit goal in the system prompt. The chain-of-thought indicated that the model was trying to avoid the unlearning procedure in order to be deployed in a manner that would be most helpful. More general settings: Firstly, in order to be more confident of the results’ generality, we broadened our sandbagging setup [...]
Outline:
(00:29) sonnet-3.5 sandbags to preserve capabilities (App. B.6)
(04:02) o1 and opus-3 can scheme to undermine pro-social goals (App. B.5)
The original text contained 3 images which were described by AI.
First published: December 17th, 2024
---
Narrated by TYPE III AUDIO).
Images from the article: