ThursdAI - Sep 19 - 👑 Qwen 2.5 new OSS king LLM, MSFT new MoE, Nous Research's Forge announcement, and Talking AIs in the open source!

ThursdAI - The top AI news from the past week
Shownotes Transcript
Hey folks, Alex here, back with another ThursdAI recap – and let me tell you, this week's episode was a whirlwind of open-source goodness, mind-bending inference techniques, and a whole lotta talk about talking AIs! We dove deep into the world of LLMs, from Alibaba's massive Qwen 2.5 drop to the quirky, real-time reactions of Moshi.
We even got a sneak peek at Nous Research's ambitious new project, Forge, which promises to unlock some serious LLM potential. So grab your pumpkin spice latte (it's that time again isn't it? 🍁) settle in, and let's recap the AI awesomeness that went down on ThursdAI, September 19th!
ThursdAI is brought to you (as always) by Weights & Biases, we still have a few spots left in our Hackathon) this weekend and our new advanced RAG course is now released and is FREE) to sign up!
TL;DR of all topics + show notes and links
Open Source LLMs
Alibaba Qwen 2.5 models drop + Qwen 2.5 Math and Qwen 2.5 Code (X), HF, Blog), Try It))
Qwen 2.5 Coder 1.5B is running on a 4 year old phone (Nisten))
KyutAI open sources Moshi & Mimi (Moshiko & Moshika) - end to end voice chat model (X, HF, Paper))
Microsoft releases GRIN-MoE - tiny (6.6B active) MoE with 79.4 MMLU (X), HF), GIthub))
Nvidia - announces NVLM 1.0 - frontier class multimodal LLMS (no weights yet, X))
Big CO LLMs + APIs
OpenAI O1 results from LMsys do NOT disappoint - vibe checks also confirm, new KING llm in town (Thread))
NousResearch announces Forge in waitlist - their MCTS enabled inference product (X))
**This weeks Buzz - **everything **Weights & Biases **related this week
Judgement Day (hackathon) is in 2 days! Still places to come hack with us Sign up)
Our new RAG Course is live - learn all about advanced RAG from WandB, Cohere and Weaviate (sign up for free))
Vision & Video
Youtube announces DreamScreen - generative AI image and video in youtube shorts ( Blog))
CogVideoX-5B-I2V - leading open source img2video model (X), HF))
Runway, DreamMachine & Kling all announce text-2-video over API (Runway), DreamMachine))
Runway announces video 2 video model (X))
Tools
Snap announces their XR glasses - have hand tracking and AI features (X))
Open Source Explosion!
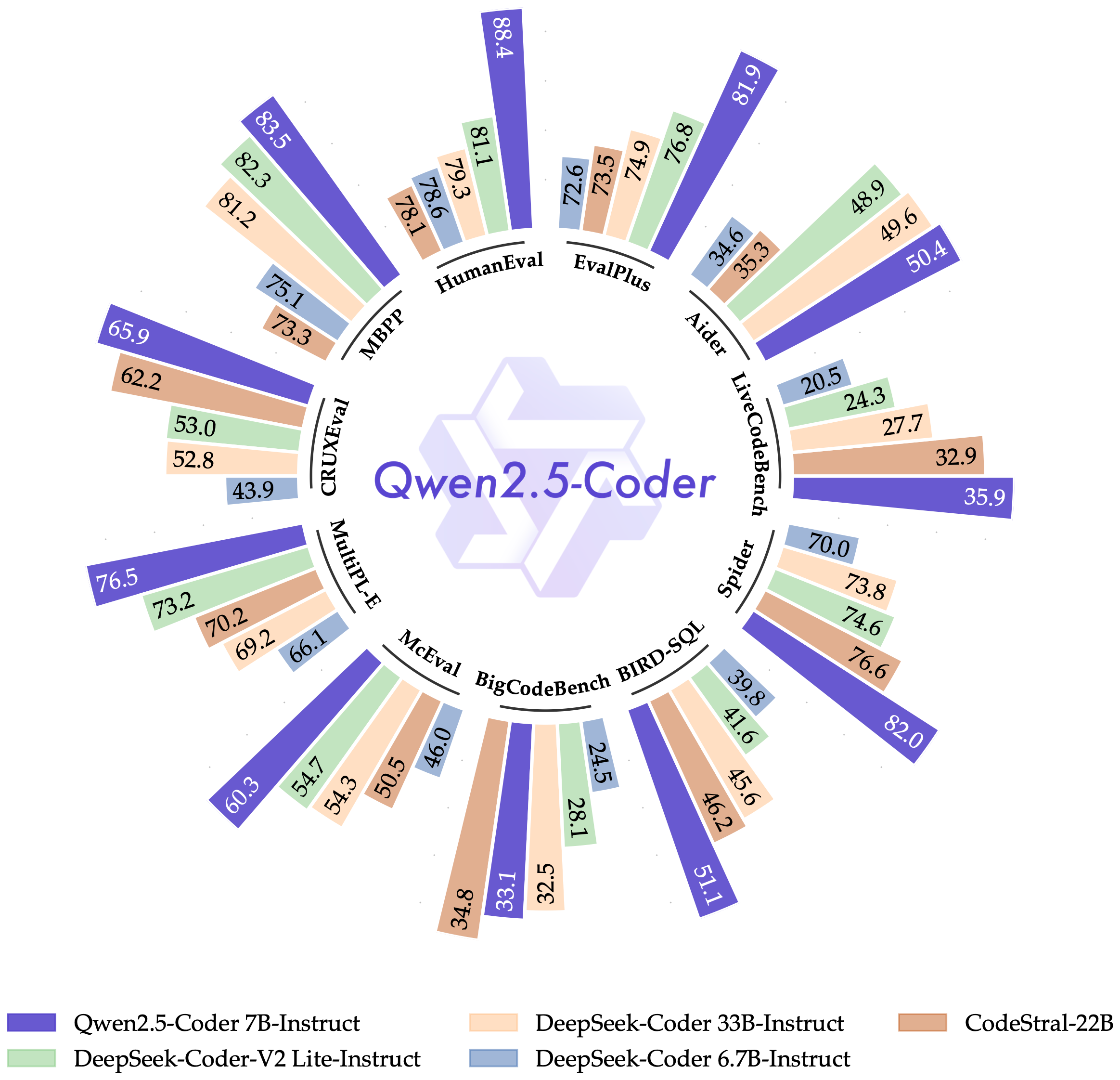
👑 Qwen 2.5: new king of OSS llm models with 12 model releases, including instruct, math and coder versions
This week's open-source highlight was undoubtedly the release of Alibaba's Qwen 2.5 models. We had Justin Lin from the Qwen team join us live to break down this monster drop, which includes a whopping seven different sizes, ranging from a nimble 0.5B parameter model all the way up to a colossal 72B beast! And as if that wasn't enough, they also dropped Qwen 2.5 Coder and Qwen 2.5 Math models, further specializing their LLM arsenal. As Justin mentioned, they heard the community's calls for 14B and 32B models loud and clear – and they delivered! "We do not have enough GPUs to train the models," Justin admitted, "but there are a lot of voices in the community...so we endeavor for it and bring them to you." Talk about listening to your users!
Trained on an astronomical 18 trillion tokens (that’s even more than Llama 3.1 at 15T!), Qwen 2.5 shows significant improvements across the board, especially in coding and math. They even open-sourced the previously closed-weight Qwen 2 VL 72B, giving us access to the best open-source vision language models out there. With a 128K context window, these models are ready to tackle some serious tasks. As Nisten exclaimed after putting the 32B model through its paces, "It's really practical…I was dumping in my docs and my code base and then like actually asking questions."
It's safe to say that Qwen 2.5 coder is now the best coding LLM that you can use, and just in time for our chat, a new update from ZeroEval confirms, Qwen 2.5 models are the absolute kings of OSS LLMS, beating Mistral large, 4o-mini, Gemini Flash and other huge models with just 72B parameters 👏
Moshi: The Chatty Cathy of AI
We've covered Moshi Voice back in July), and they have promised to open source the whole stack, and now finally they did! Including the LLM and the Mimi Audio Encoder!
This quirky little 7.6B parameter model is a speech-to-speech marvel, capable of understanding your voice and responding in kind. It's an end-to-end model, meaning it handles the entire speech-to-speech process internally, without relying on separate speech-to-text and text-to-speech models.
While it might not be a logic genius, Moshi's real-time reactions are undeniably uncanny. Wolfram Ravenwolf described the experience: "It's uncanny when you don't even realize you finished speaking and it already starts to answer." The speed comes from the integrated architecture and efficient codecs, boasting a theoretical response time of just 160 milliseconds!
Moshi uses (also open sourced) Mimi neural audio codec, and achieves 12.5 Hz representation with just 1.1 kbps bandwidth.
You can download it and run on your own machine or give it a try here) just don't expect a masterful conversationalist hehe
Gradient-Informed MoE (GRIN-MoE): A Tiny Titan
Just before our live show, Microsoft dropped a paper on GrinMoE, a gradient-informed Mixture of Experts model. We were lucky enough to have the lead author, Liyuan Liu (aka Lucas), join us impromptu to discuss this exciting development. Despite having only 6.6B active parameters (16 x 3.8B experts), GrinMoE manages to achieve remarkable performance, even outperforming larger models like Phi-3 on certain benchmarks. It's a testament to the power of clever architecture and training techniques. Plus, it's open-sourced under the MIT license, making it a valuable resource for the community.
NVIDIA NVLM: A Teaser for Now
NVIDIA announced NVLM 1.0, their own set of multimodal LLMs, but alas, no weights were released. We’ll have to wait and see how they stack up against the competition once they finally let us get our hands on them. Interestingly, while claiming SOTA on some vision tasks, they haven't actually compared themselves to Qwen 2 VL, which we know is really really good at vision tasks 🤔
Nous Research Unveils Forge: Inference Time Compute Powerhouse (beating o1 at AIME Eval!)
Fresh off their NousCon event, Karan and Shannon from Nous Research joined us to discuss their latest project, Forge. Described by Shannon as "Jarvis on the front end," Forge is an inference engine designed to push the limits of what’s possible with existing LLMs. Their secret weapon? Inference-time compute. By implementing sophisticated techniques like Monte Carlo Tree Search (MCTS), Forge can outperform larger models on complex reasoning tasks beating OpenAI's o1-preview at the AIME Eval, competition math benchmark, even with smaller, locally runnable models like Hermes 70B. As Karan emphasized, “We’re actually just scoring with Hermes 3.1, which is available to everyone already...we can scale it up to outperform everything on math, just using a system like this.”
Forge isn't just about raw performance, though. It's built with usability and transparency in mind. Unlike OpenAI's 01, which obfuscates its chain of thought reasoning, Forge provides users with a clear visual representation of the model's thought process. "You will still have access in the sidebar to the full chain of thought," Shannon explained, adding, “There’s a little visualizer and it will show you the trajectory through the tree… you’ll be able to see exactly what the model was doing and why the node was selected.” Forge also boasts built-in memory, a graph database, and even code interpreter capabilities, initially supporting Python, making it a powerful platform for building complex LLM applications.
Forge is currently in a closed beta, but a waitlist is open for eager users. Karan and Shannon are taking a cautious approach to the rollout, as this is Nous Research’s first foray into hosting a product. For those lucky enough to gain access, Forge offers a tantalizing glimpse into the future of LLM interaction, promising greater transparency, improved reasoning, and more control over the model's behavior.
For ThursdAI readers early, here's a waitlist form) to test it out!
Big Companies and APIs: The Reasoning Revolution
OpenAI’s 01: A New Era of LLM Reasoning
The big story in the Big Tech world is OpenAI's 01. Since we covered it live last week as it dropped, many of us have been playing with these new reasoning models, and collecting "vibes" from the community. These models represent a major leap in reasoning capabilities, and the results speak for themselves.
01 Preview claimed the top spot across the board on the LMSys Arena leaderboard, demonstrating significant improvements in complex tasks like competition math and coding. Even the smaller 01 Mini showed impressive performance, outshining larger models in certain technical areas. (and the jump in ELO score above the rest in MATH is just incredible to see!) and some folks made this video viral, of a PHD candidate reacting to 01 writing in 1 shot, code that took him a year to write, check it out, it’s priceless.
One key aspect of 01 is the concept of “inference-time compute”. As Noam Brown from OpenAI calls it, this represents a "new scaling paradigm", allowing the model to spend more time “thinking” during inference, leading to significantly improved performance on reasoning tasks. The implications of this are vast, opening up the possibility of LLMs tackling long-horizon problems in areas like drug discovery and physics.
However, the opacity surrounding 01’s chain of thought reasoning being hidden/obfuscated and the ban on users asking about it was a major point of contention at least within the ThursdAI chat. As Wolfram Ravenwolf put it, "The AI gives you an answer and you can't even ask how it got there. That is the wrong direction." as he was referring to the fact that not only is asking about the reasoning impossible, some folks were actually getting threatening emails and getting banned from using the product all together 😮
This Week's Buzz: Hackathons and RAG Courses!
We're almost ready to host our Weights & Biases Judgment Day Hackathon) (LLMs as a judge, anyone?) with a few spots left, so if you're reading this and in SF, come hang out with us!
And the main thing I gave an update about is our Advanced RAG course), packed with insights from experts at Weights & Biases, Cohere, and Weaviate. Definitely check those out if you want to level up your LLM skills (and it's FREE) in our courses academy!)
Vision & Video: The Rise of Generative Video
Generative video is having its moment, with a flurry of exciting announcements this week. First up, the open-source CogVideoX-5B-I2V, which brings accessible image-to-video capabilities to the masses. It's not perfect, but being able to generate video on your own hardware is a game-changer.
On the closed-source front, YouTube announced the integration of generative AI into YouTube Shorts with their DreamScreen feature, bringing AI-powered video generation to a massive audience. We also saw API releases from three leading video model providers: Runway, DreamMachine, and Kling, making it easier than ever to integrate generative video into applications. Runway even unveiled a video-to-video model, offering even more control over the creative process, and it's wild, check out what folks are doing with video-2-video!
One last thing here, Kling is adding a motion brush feature to help users guide their video generations, and it just looks so awesome I wanted to show you
Whew! That was one hell of a week, tho from the big companies perspective, it was a very slow week, getting a new OSS king, an end to end voice model and a new hint of inference platform from Nous, and having all those folks come to the show was awesome!
If you're reading all the way down to here, it seems that you like this content, why not share it with 1 or two friends? 👇 And as always, thank you for reading and subscribing! 🫶
P.S - I’m traveling for the next two weeks, and this week the live show was live recorded from San Francisco, thanks to my dear friends swyx & Alessio) for hosting my again in their awesome Latent Space) pod studio at Solaris SF)!
This is a public episode. If you’d like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe)