📅 ThursdAI - May 30 - 1000 T/s inference w/ SambaNova, <135ms TTS with Cartesia, SEAL leaderboard from Scale & more AI news

ThursdAI - The top AI news from the past week
Shownotes Transcript
Hey everyone, Alex here!
Can you believe it's already end of May? And that 2 huge AI companies conferences are behind us (Google IO, MSFT Build) and Apple's WWDC is just ahead in 10 days! Exciting!
I was really looking forward to today's show, had quite a few guests today, I'll add all their socials below the TL;DR so please give them a follow and if you're only in reading mode of the newsletter, why don't you give the podcast a try 🙂 It's impossible for me to add the density of knowledge that's being shared on stage for 2 hours here in the newsletter!
Also, before we dive in, I’m hosting a free workshop soon, about building evaluations from scratch, if you’re building anything with LLMs in production, more than welcome to join us on June 12th) (it’ll be virtual)
TL;DR of all topics covered:
Open Source LLMs
Mistral open weights Codestral - 22B dense coding model (X), Blog))
Nvidia open sources NV-Embed-v1 - Mistral based SOTA embeddings (X), HF))
HuggingFace Chat with tool support (X), demo))
Aider beats SOTA on Swe-Bench with 26% (X), Blog), Github))
OpenChat - Sota finetune of Llama3 (X), HF), Try It))
LLM 360 - K2 65B - fully transparent and reproducible (X), Paper), HF), WandB))
Big CO LLMs + APIs
Scale announces SEAL Leaderboards - with private Evals (X), leaderboard))
SambaNova achieves >1000T/s on Llama-3 full precision
Groq hits back with breaking 1200T/s on Llama-3
Anthropic tool support in GA (X), Blogpost))
OpenAI adds GPT4o, Web Search, Vision, Code Interpreter & more to free users (X))
Google Gemini & Gemini Flash are topping the evals leaderboards, in GA(X))
Gemini Flash finetuning coming soon
This weeks Buzz (What I learned at WandB this week)
Sponsored a Mistral hackathon in Paris
We have an upcoming workshop) in 2 parts - come learn with me
Vision & Video
LLama3-V - Sota OSS VLM (X), Github))
Voice & Audio
Cartesia AI - super fast SSM based TTS with very good sounding voices (X), Demo))
Tools & Hardware
Jina Reader (https://jina.ai/reader/))
Co-Hosts and Guests
Rodrigo Liang (@RodrigoLiang)) & Anton McGonnell (@aton2006)) from SambaNova
Itamar Friedman (@itamar_mar)) Codium
Arjun Desai (@jundesai)) - Cartesia
Nisten Tahiraj (@nisten)) - Cohost
Wolfram Ravenwolf (@WolframRvnwlf))
Eric Hartford (@erhartford))
Maziyar Panahi (@MaziyarPanahi))
Scale SEAL leaderboards (Leaderboard))
Scale AI has announced their new initiative, called SEAL leaderboards, which aims to provide yet another point of reference in how we understand frontier models and their performance against each other.
We've of course been sharing LMSys arena rankings here, and openLLM leaderboard from HuggingFace, however, there are issues with both these approaches, and Scale is approaching the measuring in a different way, focusing on very private benchmarks and dataset curated by their experts (Like Riley Goodside)
The focus of SEAL is private and novel assessments across Coding, Instruction Following, Math, Spanish and more, and the main reason they keep this private, is so that models won't be able to train on these benchmarks if they leak to the web, and thus show better performance due to data contamination.
They are also using ELO scores (Bradley-Terry) and I love this footnote from the actual website:
"To ensure leaderboard integrity, we require that models can only be featured the FIRST TIME when an organization encounters the prompts"
This means they are taking the contamination thing very seriously and it's great to see such dedication to being a trusted source in this space.
Specifically interesting also that on their benchmarks, GPT-4o is not better than Turbo at coding, and definitely not by 100 points like it was announced by LMSys and OpenAI when they released it!
Gemini 1.5 Flash (and Pro) in GA and showing impressive performance
As you may remember from my Google IO recap), I was really impressed with Gemini Flash, and I felt that it went under the radar for many folks. Given it's throughput speed, 1M context window, and multimodality and price tier, I strongly believed that Google was onto something here.
Well this week, not only was I proven right, I didn't actually realize how right I was 🙂 as we heard breaking news from Logan Kilpatrick during the show, that the models are now in GA, and that Gemini Flash gets upgraded to 1000 RPM (requests per minute) and announced that finetuning is coming and will be free of charge!
Not only with finetuning won't cost you anything, inference on your tuned model is going to cost the same, which is very impressive.
There was a sneaky price adjustment from the announced pricing to the GA pricing that upped the pricing by 2x on output tokens, but even despite that, Gemini Flash with $0.35/1MTok for input and $1.05/1MTok on output is probably the best deal there is right now for LLMs of this level.
This week it was also confirmed both on LMsys, and on Scale SEAL leaderboards that Gemini Flash is a very good coding LLM, beating Claude Sonnet and LLama-3 70B!
SambaNova + Groq competing at 1000T/s speeds
What a week for inference speeds!
SambaNova (an AI startup with $1.1B in investment from Google Ventures, Intel Capital, Samsung, Softbank founded in 2017) has announced that they broke the 1000T/s inference barrier on Llama-3-8B in full precision mode (suing their custom hardware called RDU (reconfigurable dataflow unit)
As you can see, this is incredible fast, really, try it yourself here).
Seeing this, the folks at Groq, who had the previous record on super fast inference (as I reported just in February)) decided to not let this slide, and released an incredible 20% improvement on their own inference of LLama-3-8B, getting to 1200Ts, showing that they are very competitive.
This bump in throughput is really significant, many inference providers that use GPUs, and not even hitting 200T/s, and Groq improved their inference by that amount within 1 day of being challenged.
I had the awesome pleasure to have Rodrigo the CEO on the show this week to chat about SambaNova and this incredible achievement, their ability to run this in full precision, and future plans, so definitely give it a listen.
This weeks Buzz (What I learned with WandB this week)
This week was buzzing at Weights & Biases! After co-hosting a Hackathon with Meta a few weeks ago, we cohosted another Hackathon, this time with Mistral, in Paris. (where we also announced our new integration with their Finetuning!)
The organizers Cerebral Valley have invited us to participate and it was amazing to see the many projects that use WandB and Weave in their finetuning presentations, including a friend of the pod Maziyar Panahi who's team nabbed 2nd place (you can read about their project here)) 👏
Also, I'm going to do a virtual workshop together with my colleague Anish, about prompting and building evals, something we know a thing or two about, it's free and I would very much love to invite you to register and learn with us)!
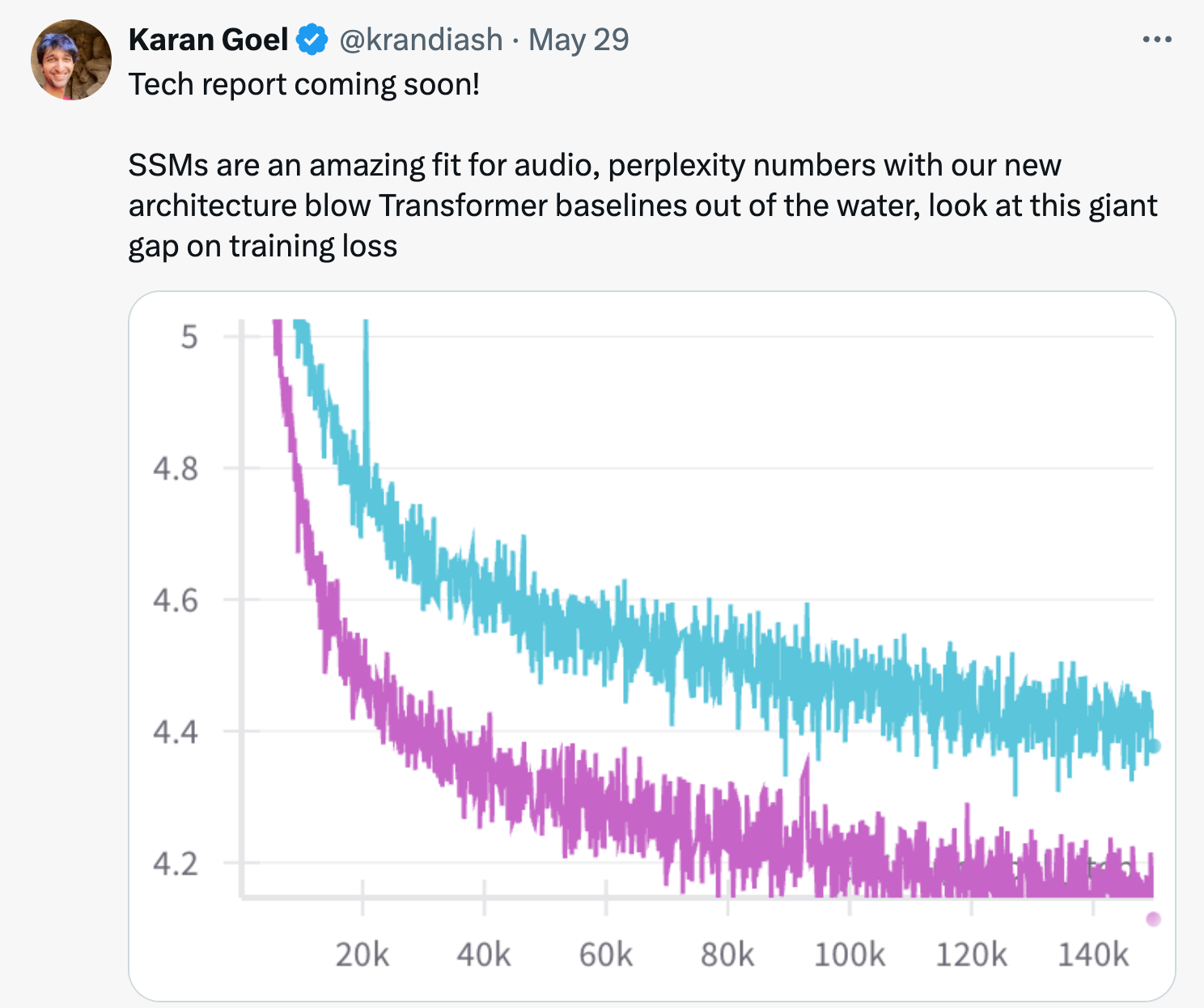
Cartesia AI (try it))
Hot off the press, we're getting a new Audio TTS model, based on the State Space model architecture (remember Mamba?) from a new startup called Cartesia AI, who aim to bring real time intelligence to on device compute!
The most astonishing thing they released was actually the speed with which they model starts to generate voices, under 150ms, which is effectively instant, and it's a joy to play with their playground), just look at how fast it started generating this intro I recorded using their awesome 1920's radio host voice
Co-founded by Albert Gu, Karan Goel and Arjun Desai (who joined the pod this week) they have shown incredible performance but also showed that transformer alternative architectures like SSMs can really be beneficial for audio specifically, just look at this quote!
On speech, a parameter-matched and optimized Sonic model trained on the same data as a widely used Transformer improves audio quality significantly (20% lower perplexity, 2x lower word error, 1 point higher NISQA quality).
With lower latency (1.5x lower time-to-first-audio), faster inference speed (2x lower real-time factor) and higher throughput (4x)
In Open Source news:
Mistral released Codestral 22B - their flagship code model with a new non commercial license
Codestral is now available under the new Mistral license for non-commercial R&D use. With a larger context window of 32K, Codestral outperforms all other models in RepoBench, a long-range evaluation for code generation. Its fill-in-the-middle capability is favorably compared to DeepSeek Coder 33B.
Codestral is supported in VSCode via a plugin and is accessible through their API, Le Platforme, and Le Chat.
HuggingFace Chat with tool support (X), demo))
This one is really cool, HF added Cohere's Command R+ with tool support and the tools are using other HF spaces (with ZeroGPU) to add capabilities like image gen, image editing, web search and more!
LLM 360 - K2 65B - fully transparent and reproducible (X), Paper), HF), WandB))
The awesome team at LLM 360 released K2 65B, which is an open source model that comes very close to LLama70B on benchmarks, but the the most important thing, is that they open source everything, from code, to datasets, to technical write-ups, they even open sourced their WandB plots 👏
This is so important to the open source community, that we must highlight and acknowledge the awesome effort from LLM360 ai of doing as much open source!
Tools - Jina reader
In the tools category, while we haven't discussed this on the pod, I really wanted to highlight Jina reader. We've had Bo from Jina AI talk to us about Embeddings in the past episodes, and since then Jina folks released this awesome tool that's able to take any URL and parse it in a nice markdown format that's very digestable to LLMs.
You can pass any url, and it even does vision understanding! And today they released PDF understanding as well so you can pass the reader PDF files and have it return a nicely formatted text!
The best part, it's free! (for now at least!)
And that’s a wrap for today, see you guys next week, and if you found any of this interesting, please share with a friend 🙏 This is a public episode. If you’d like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe)