📅 ThursdAI - Jun 6th - 👑 Qwen2 Beats Llama-3! Jina vs. Nomic for Multimodal Supremacy, new Chinese SORA, Suno & Udio user uploads & more AI news

ThursdAI - The top AI news from the past week
Shownotes Transcript
Hey hey! This is Alex! 👋
Some podcasts have 1 or maaaybe 2 guests an episode, we had 6! guests today, each has had an announcement, an open source release, or a breaking news story that we've covered! (PS, this edition is very multimodal so click into the Substack as videos don't play in your inbox)
As you know my favorite thing is to host the folks who make the news to let them do their own announcements, but also, hitting that BREAKING NEWS button when something is actually breaking (as in, happened just before or during the show) and I've actually used it 3 times this show!
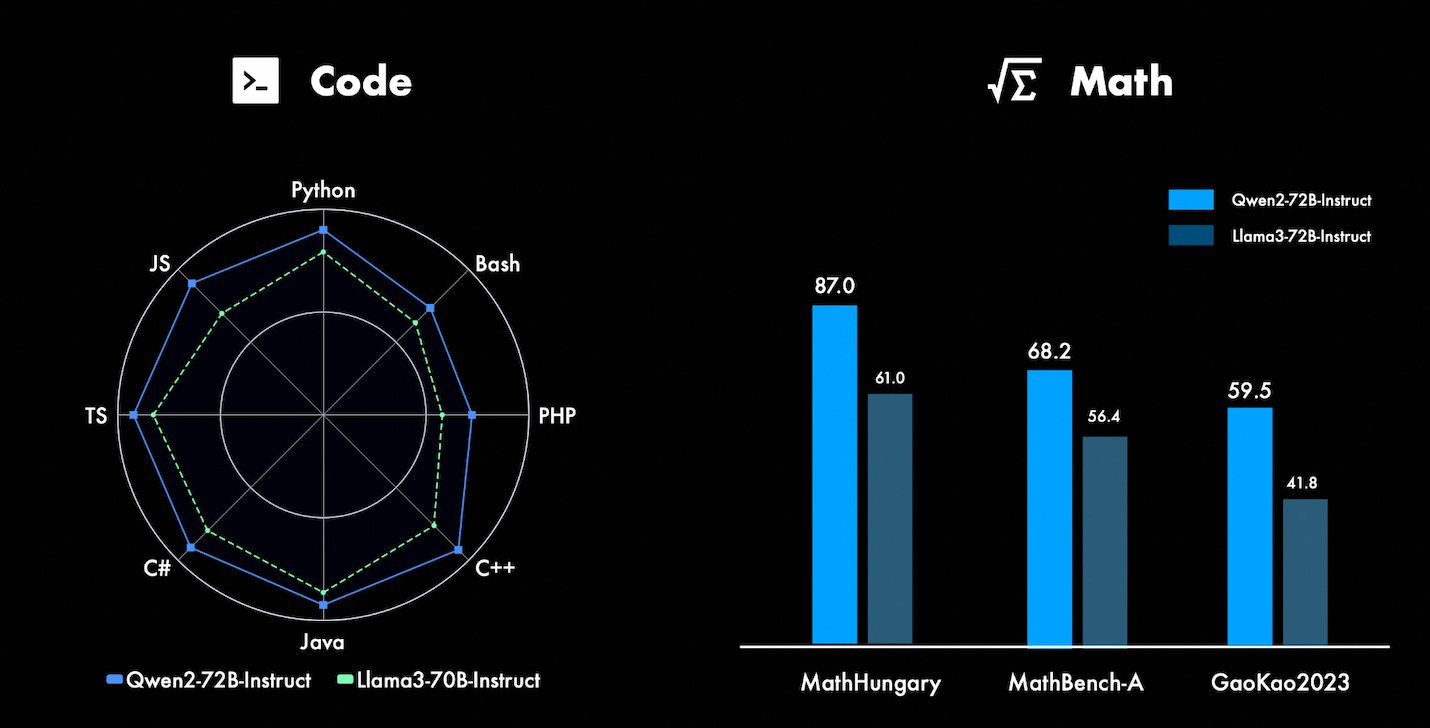
It's not every week that we get to announce a NEW SOTA open model with the team that worked on it. Junyang (Justin) Lin from Qwen is a friend of the pod, a frequent co-host, and today gave us the breaking news of this month, as Qwen2 72B, is beating LLama-3 70B on most benchmarks! That's right, a new state of the art open LLM was announced on the show, and Justin went deep into details 👏 (so don't miss this conversation, listen to wherever you get your podcasts)
We also chatted about SOTA multimodal embeddings with Jina folks (Bo Wand and Han Xiao) and Zach from Nomic, dove into an open source compute grant with FALs Batuhan Taskaya and much more!
TL;DR of all topics covered:
**Open Source LLMs **
Alibaba announces Qwen 2 - 5 model suite (X), HF))
Jina announces Jina-Clip V1 - multimodal embeddings beating CLIP from OAI (X), Blog), Web Demo))
Nomic announces Nomic-Embed-Vision (X), BLOG))
MixEval - arena style rankings with Chatbot Arena model rankings with 2000× less time (5 minutes) and 5000× less cost ($0.6) (*X)*, *Blog)*)
Vision & Video
Kling - open access video model SORA competitor from China (X))
This Weeks Buzz
WandB supports Mistral new finetuning service (X)
Register to my June 12 workshop on building Evals with Weave HERE)
Voice & Audio
StableAudio Open - X), BLOG), TRY IT)
Suno launches "upload your audio" feature to select few - X)
Udio - upload your own audio feature - X)
AI Art & Diffusion & 3D
Stable Diffusion 3 weights are coming on June 12th (Blog))
JasperAI releases Flash Diffusion (X), TRY IT), Blog))
Big CO LLMs + APIs
Group of ex-OpenAI sign a new letter - righttowarn.ai)
A hacker releases TotalRecall - a tool to extract all the info from MS Recall Feature (Github))
Open Source LLMs
QWEN 2 - new SOTA open model from Alibaba (X), HF))
This is definitely the biggest news for this week, as the folks at Alibaba released a very surprising and super high quality suite of models, spanning from a tiny 0.5B model to a new leader in open models, Qwen 2 72B
To add to the distance from Llama-3, these new models support a wide range of context length, all large, with 7B and 72B support up to 128K context.
Justin mentioned on stage that actually finding sequences of longer context lengths is challenging, and this is why they are only at 128K.
In terms of advancements, the highlight is advanced Code and Math capabilities, which are likely to contribute to overall model advancements across other benchmarks as well.
It's also important to note that all models (besides the 72B) are now released with Apache 2 license to help folks actually use globally, and speaking of globality, these models have been natively trained with 27 additional languages, making them considerably better at multilingual prompts!
One additional amazing thing was, that a finetune was released by Eric Hartford and Cognitive Computations team, and AFAIK this is the first time a new model drops with an external finetune. Justing literally said "It is quite amazing. I don't know how they did that. Well, our teammates don't know how they did that, but, uh, it is really amazing when they use the Dolphin dataset to train it."
Here's the Dolphin finetune metrics and you can try it out) here
ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Jina-Clip V1 and Nomic-Embed-Vision SOTA multimodal embeddings
It's quite remarkable that we got 2 separate SOTA of a similar thing during the same week, and even more cool that both companies came to talk about it on ThursdAI!
First we welcomed back Bo Wang from Jina (who joined by Han Xiao the CEO) and Bo talked about multimodal embeddings that beat OpenAI CLIP (which both conceded was a very low plank)
Jina Clip V1 is apache 2 open sourced, while Nomic Embed is beating it on benchmarks but is CC-BY-NC non commercially licensed, but in most cases, if you're embedding, you'd likely use an API, and both companies offer these embeddings via their respective APIs
One thing to note about Nomic, is that they have mentioned that these new embeddings are backwards compatible with the awesome Nomic embed endpoints and embeddings, so if you've used that, now you've gone multimodal!
Because these models are fairly small, there are now web versions, thanks to transformer.js, of Jina) and Nomic Embed) (caution, this will download large-ish files) built by non other than our friend Xenova.
If you're building any type of multimodal semantic search, these two embeddings systems are now open up all your RAG needs for multi modal data!
This weeks Buzz (What I learned with WandB this week)
Mistral announced built in finetuning server support, and has a simple WandB integration! (X))
Also, my workshop about building evals 101 is coming up next week, June 12, excited to share with you a workshop that we wrote for in person crowd, please register here)
and hope to see you next week!
Vision & Video
New SORA like video generation model called KLING in open access (DEMO))
This one has to be seen to be believed, out of nowhere, an obscure (to us) chinese company kuaishou.com) dropped a landing page with tons of videos that are clearly AI generated, and they all look very close to SORA quality, way surpassing everything else we've seen in this category (Runaway, Pika, SVD)
And they claim that they offer support for it via their App (but you need apparently a Chinese phone number, so not for me)
It's really hard to believe that this quality exists already outside of a frontier lab full of GPUs like OpenAI and it's now in waitlist mode, where as SORA is "coming soon"
Voice & Audio
Stability open sources Stable Audio Open (X), BLOG), TRY IT))
A new open model from Stability is always fun, and while we wait for SD3 to drop weights (June 12! we finally have a date) we get this awesome model from Dadabots at team at Stability.
It's able to generate 47s seconds of music, and is awesome at generating loops, drums and other non vocal stuff, so not quite where Suno/Udio are, but the samples are very clean and sound very good. Prompt: New York Subway
They focus the model on being able to get Finetuned on a specific drummers style for example, and have it be open and specialize in samples, and sound effects and not focused on melodies or finalized full songs but it has some decent skills in simple prompts, like "progressive house music"
This model has a non commercial license and can be played with here)
Suno & Udio let users upload their own audio!
This one is big, so big in fact, that I am very surprised that both companies announced this exact feature the same week.
Suno has reached out to me and a bunch of other creators, and told us that we are now able to upload our own clips, be it someone playing solo guitar, or even whistling and have Suno remix it into a real proper song.
In this example, this is a very viral video, this guy sings at a market selling fish (to ladies?) and Suno was able to create this remix for me, with the drop, the changes in his voice, the melody, everything, it’s quite remarkable!
AI Art & Diffusion
Flash Diffusion from JasperAI / Clipdrop team (X), TRY IT), Blog), Paper))
Last but definitely not least, we now have a banger of a diffusion update, from the Clipdrop team (who was *amazing *things before Stability bought them and then sold them to JasperAI)
Diffusion models likle Stable Diffusion often take 30-40 inference steps to get you the image, searching for your prompt through latent space you know?
Well recently there have been tons of these new distill methonds, models that are like students, who learn from the teacher model (Stable Diffusion XL for example) and distill the same down to a few steps (sometimes as low as 2!)
Often the results are, distilled models that can run in real time, like SDXL Turbo, Lightning SDXL etc
Now Flash Diffusion achieves State-of-the-Art (SOTA) performance metrics, specifically in terms of Fréchet Inception Distance (FID) and CLIP Score. These metrics are the default for evaluating the quality and relevance of generated images.
And Jasper has open sourced the whole training code to allow for reproducibility which is very welcome!
Flash diffusion also comes in not only image generation, but also inpaining and upscaling, allowing it to be applied to other methods to speed them up as well.
—
This is all for this week, I mean, there are TONS more stuff we could have covered, and we did mention them on the pod, but I aim to serve as a filter to the most interesting things as well so, until next week 🫡 This is a public episode. If you’d like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe)