ThursdAI Aug 3 - OpenAI, Qwen 7B beats LLaMa, Orca is replicated, and more AI news

ThursdAI - The top AI news from the past week
Shownotes Transcript
Hi, today’s episode is published on a Friday, it’s been a busy week with at least 4 twitter spaces, countless DMs and research!
OpenAI announces UX updates
Example prompts: No more staring at a blank page!
Suggested replies: ChatGPT automatically synthesizes follow up questions. Then you just click a button
GPT-4 by default: When starting a new chat as a Plus user, ChatGPT will remember your previously selected model!
- Uploading multiple files is now supported in the Code Interpreter beta for all Plus users.
- Stay logged in: You’ll no longer be logged out every 2 weeks and if you do, we have a sweet new welcome page!
- Keyboard shortcuts: Work faster with shortcuts, Try ⌘ (Ctrl) + / to see the complete list.
ThursdAI - I stay up to date so you don’t have to
Alibaba releases Qwen7b)
Trained with high-quality pretraining data. Qwen-7B pretrained on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.
Strong performance. In comparison with the models of the similar model size, outperforms the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
Better support of languages. New tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.
Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.
This is an impressive jump in open source capabilities, less than a month after LLaMa 2 release!
GTE-large a new embedding model outperforms OPENAI ada-002
If you’ve used any “chat with your documents” app or built one, or have used a vector database, chances are, you’ve used openAI ada-002, it’s the most common embedding model (that turns text into embeddings for vector similarity search)
This model is ousted by an OpenSource (nee. free) one called GTE-large) with improvements on top of ada across most parameters!
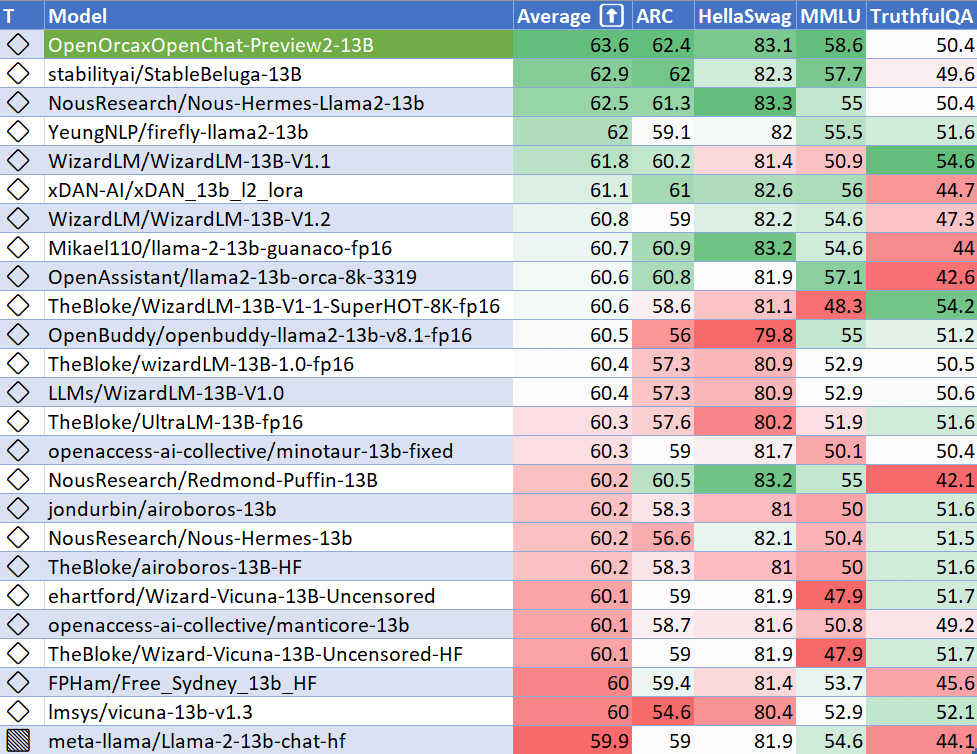
OpenOrca 2 preview
Our friends from AlignmentLab including Teknium and LDJ have discussed the release of OpenOrca 2! If you’re interested in the type of finetuning things these guys do, we had a special interview w/ NousResearch on the pod a few weeks ago
OpenOrca tops the charts for the best performing 13B model 👏
Hyper-write releases a personal assistant
You know how much we love agents in ThursdAI, and we’re waiting for this field to materialize and I personally am waiting for an agent to summarize the whole links and screenshots for this summary, and… we’re not there yet! But we’re coming close, and our friends from HyperWrite have released their browser controlling agent) on ThursdAI. Talk about a full day of releases!
I absolutely love the marketing trick they used where one of the examples of how it works, is “upvote us on producthunt” and it actually did work for me, and found out that I already upvoted)
Superconductor continues
I was absolutely worried that I won’t make it to this thursdAI or won’t know what to talk about because, well, I’ve become a sort of host and information hub) and a interviewer of folks about LK-99. Many people around the world seem interested in it’s properties, replication attempts and to understand this new and exciting thing.
We talked about this briefly, but if interests you (and I think it absolutely should) please listen to the below recording.
ThursdAI - See ya next week, don’t forget to subscribe and if you are already subscribed, and get value, upgrading will help me buy the proper equipment to make this a professional endeavor and pay for the AI tools! 🫡
This is a public episode. If you’d like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe)