
很好也很贵?OpenAI Realtime API 一手体验和 Voice AI 的未来
编码人声
Deep Dive
What is the main advantage of OpenAI's Real-Time API?
The main advantage of OpenAI's Real-Time API is its ability to provide a seamless 'voice-in, voice-out' experience, eliminating the need to chain multiple models for transcription, inference, and text-to-speech conversion. This significantly reduces latency, making interactions with AI more natural and fluid.
Why is the cost of using OpenAI's Real-Time API considered high?
The cost is high because the API processes audio data in real-time, which requires continuous high-frequency data transmission via WebSocket. Additionally, the API accumulates audio tokens from previous interactions, leading to higher token consumption as conversations progress. This results in a cost of approximately $1 per minute, making it expensive for many use cases.
What are some potential use cases for OpenAI's Real-Time API?
Potential use cases include fitness coaching, language learning, sales, customer service, AI gaming, virtual assistants, and virtual AI hosts. These applications benefit from the API's low latency and natural interaction capabilities, making them suitable for high-value scenarios where real-time communication is crucial.
How does OpenAI's Real-Time API handle interruptions in conversations?
The API supports real-time state management, allowing users to interrupt the AI mid-response. This ensures that the AI can stop speaking immediately when interrupted, enhancing the natural flow of conversation and improving user experience.
What challenges do developers face when integrating OpenAI's Real-Time API?
Developers face challenges such as the complexity of integrating WebSocket APIs, managing real-time audio data transmission, and handling network latency. Additionally, the API requires developers to manage stateful conversations, which is more complex than traditional RESTful APIs. The high cost of the API also limits its accessibility for many developers.
How does OpenAI's Real-Time API compare to traditional STT and TTS models?
OpenAI's Real-Time API bypasses the need for separate STT (Speech-to-Text) and TTS (Text-to-Speech) models by providing a direct 'voice-in, voice-out' model. This reduces latency significantly compared to traditional methods, where audio is processed asynchronously through multiple steps. However, the API still allows for optional STT and TTS integration for specific use cases.
What is the future of real-time multimodal AI according to the podcast?
The future of real-time multimodal AI involves more natural and immersive interactions, where AI can handle multiple modalities like audio, video, and text seamlessly. This will enable applications like real-time language translation, virtual assistants, and AI-driven content creation. The integration of AI into daily life will make real-time interactions more common, transforming how we communicate and interact with technology.
What role does the TEN Framework play in real-time multimodal AI?
The TEN Framework simplifies the integration of real-time multimodal AI by modularizing audio and video capabilities, making it easier for developers to combine these with AI functionalities. It focuses on providing low-latency, high-performance transmission channels and state management, enabling developers to create applications like voice-to-voice or video-to-video interactions more efficiently.
How does OpenAI's Real-Time API handle multilingual conversations?
The API supports seamless language switching, allowing users to converse in multiple languages without needing to chain separate models for each language. This capability enhances the user experience in multilingual scenarios, making it easier to interact with AI in diverse linguistic contexts.
What are the limitations of OpenAI's Real-Time API in terms of video understanding?
The API currently focuses on audio interactions and does not fully support video understanding. Video comprehension is more complex due to the lack of suitable training data and the low signal-to-noise ratio in video content. This makes it challenging for AI to interpret subtle visual cues like microexpressions, limiting its ability to fully understand and respond to video inputs.
Shownotes Transcript
OpenAI Realtime API 发布了,你准备好了么?Realtime API 让开发者可以构建近乎实时的「语音到语音」的体验,无需将多个模型拼接在一起进行转录、推理和文本到语音的转换,实现更流畅的打断体验,还可以无缝切换多种语言。本期节目请来了第一批接入并体验 OpenAI Realtime API 的开发者,为你解析背后的技术和开发者的新机会。两位嘉宾分别是在实时多模态 AI 领域深耕多年的专家——开源实时多模态 AI 框架 TEN Framework 的联合发起人 Plutoless ,以及拾象科技的 AI Research Lead 钟凯祺 Cage。节目深度分析了 OpenAI Realtime API 的优势与挑战,讨论了实时多模态 AI 如何实现语音进、语音出的端到端交互,大幅降低延迟,提升用户体验,使得与 AI 的对话更加自然流畅。也谈到了目前存在的高昂成本和技术集成的复杂性,以及这些问题对开发者意味着什么。此外,嘉宾们还深入探讨了实时多模态 AI 的定义,什么才是真正的实时多模态?他们分享了自己在实践中遇到的挑战和最佳实践,探讨了在 OpenAI Realtime API 的背景下,开发者如何抓住新的机遇。他们也展望了 AI 在未来实时互联网中的角色,讨论了 AI 安全、人与 AI 的协作、多模态交互等话题。
节目中提到的 Voice Agent 象限图:X 轴为「准确优先」到「创造力优先」,Y 轴为「实时不敏感」到「实时敏感」(「海外独角兽」制图):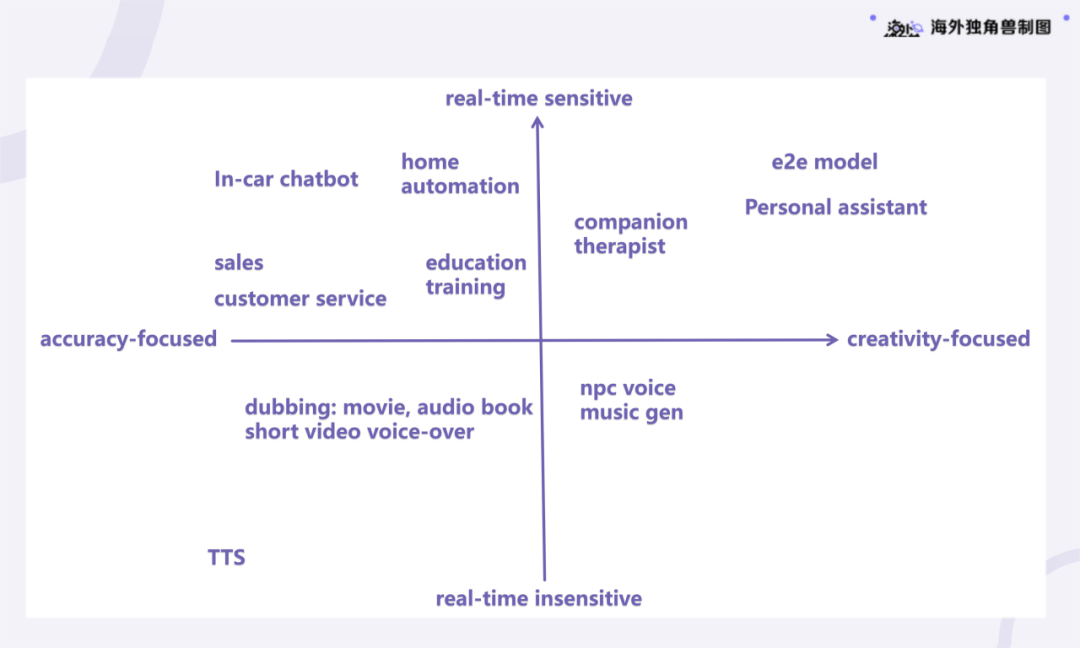
本期嘉宾和主播
- 普列思(Plutoless), 开源多模态实时互动框架 TEN Framework 的联合发起人和开发者体验负责人,RTE 开发者社区布道师。拥有多年在实时互动领域的专业从业经验。
- 钟凯祺 Cage,「海外独角兽」AI Research Lead。
- 朱峰,「津津乐道播客网络」创始人,产品及技术专家。
听友福利
10 月 25 日到 26 日,RTE 开发者社区联合声网策划的 RTE 大会 2024 将在北京举行。今年的技术论坛将覆盖音视频技术、AI 生成视频、Voice AI、多模态大模型、空间计算和新硬件、云边端架构和 AI Infra 等话题。期待与你一起探索实时互动的更多可能,咱们 10 月 25 日到 26 日,北京见!获取《编码人声》听众限免门票: https://r.daofm.cn/9fgol)
同期 AI Workshop 报名:「组装」你的专属多模态 Agent!(10 月 26 日下午,北京)https://www.bagevent.com/event/rteworkshop
相关内容
- 访问 TEN Agent),即刻体验 OpenAI Realtime API
- 开源实时多模态 AI 框架 TEN Framework)
- 嘉宾 Cage 共同撰写文章:《Voice Agent:AI 时代的交互界面,下一代 SaaS 入口)》
- 特德·姜在《纽约客》的文章: Why A.I. Isn’t Going to Make Art)
制作团队
后期 / 卷圈监制 / 姝琦产品统筹 / bobo联合制作 / RTE开发者社区
关于「编码人声」
「编码人声」是由「RTE开发者社区)」策划的一档播客节目,关注行业发展变革、开发者职涯发展、技术突破以及创业创新,由开发者来分享开发者眼中的工作与生活。录制嘉宾覆盖信通院 & 科委专家、国内外资深投资人、VR/AR & 虚拟人 & AIGC 等新兴技术领域头部创业者、一线网红 & 硬核开发者、跨界画家 & 作家 & 酿酒师等。
RTE 开发者社区)是聚焦实时互动领域的中立开发者社区。不止于纯粹的技术交流,我们相信开发者具备更加丰盈的个体价值。行业发展变革、开发者职涯发展、技术创业创新资源,我们将陪跑开发者,共享、共建、共成长。社区于2023年底正式启动了「主理人+工作组」的运营机制,并确认了社区的 3 位联合主理人 ——· 零一万物 01.AI 开源负责人 @林旅强 Richard**· FreeSWITCH 中文社区创始人 @杜金房·** 小红书音视频架构负责人 @陈靖
本节目由津津乐道播客网络与 RTE 开发者社区)联合制作播出。
RTE 开发者社区) | 公众号:RTE开发者社区 | 津津乐道播客官网) | 版权声明) | 评论须知) | 加入听友群)
{kind=link}