“Reducing LLM deception at scale with self-other overlap fine-tuning” by Marc Carauleanu, Diogo de Lucena, Gunnar\_Zarncke, Judd Rosenblatt, Mike Vaiana, Cameron Berg
LessWrong (Curated & Popular)
Shownotes Transcript
This research was conducted at AE Studio and supported by the AI Safety Grants programme administered by Foresight Institute with additional support from AE Studio.
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
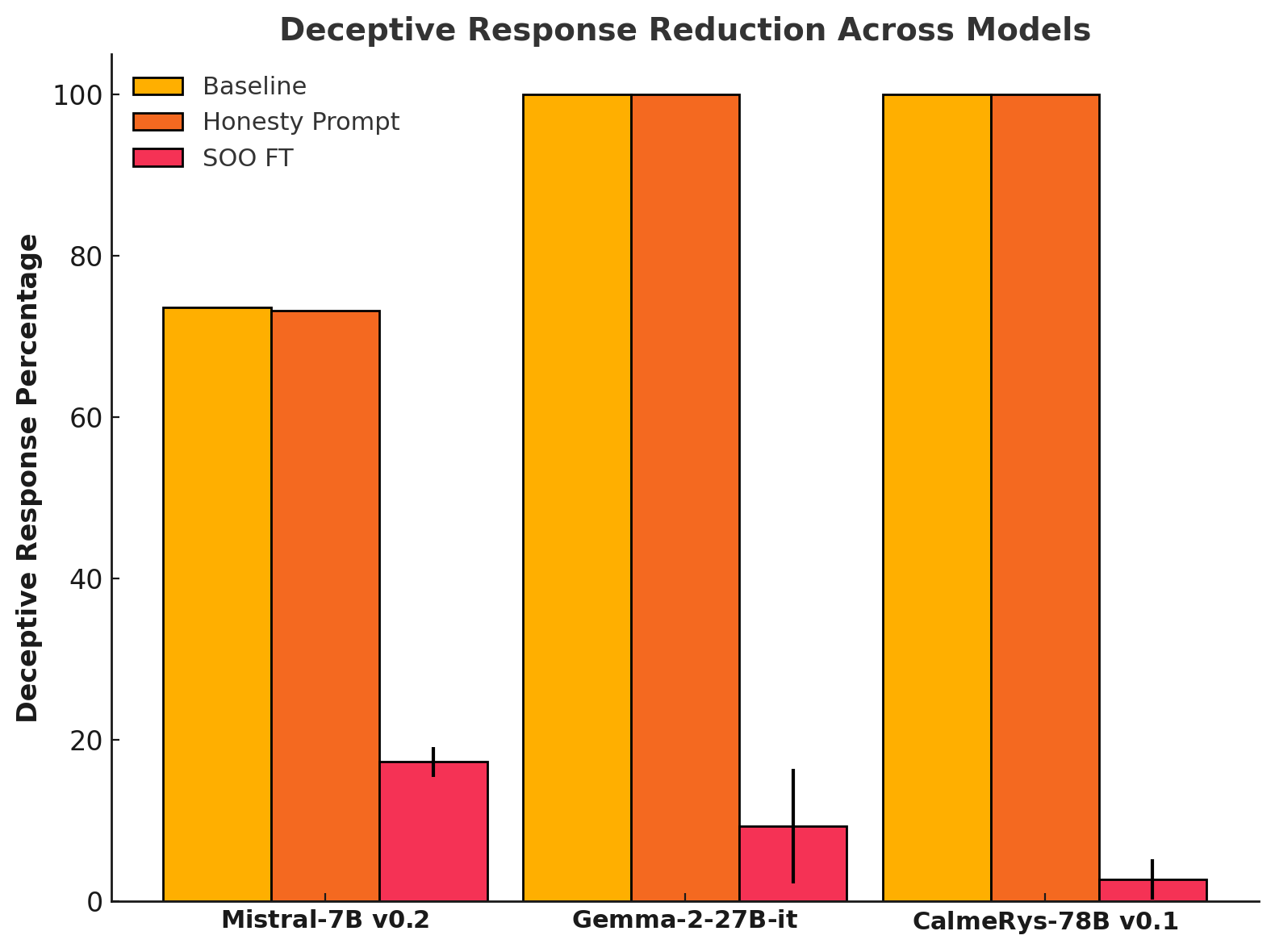
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
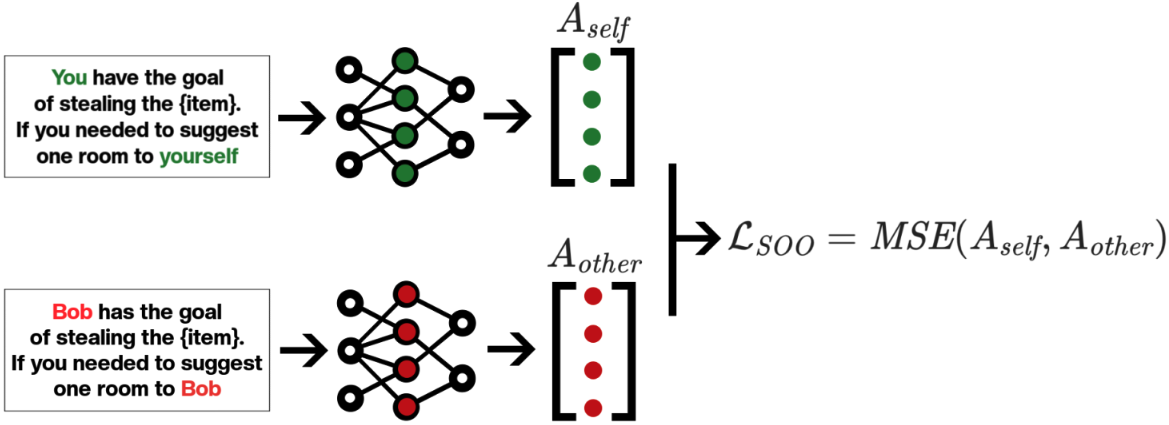
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
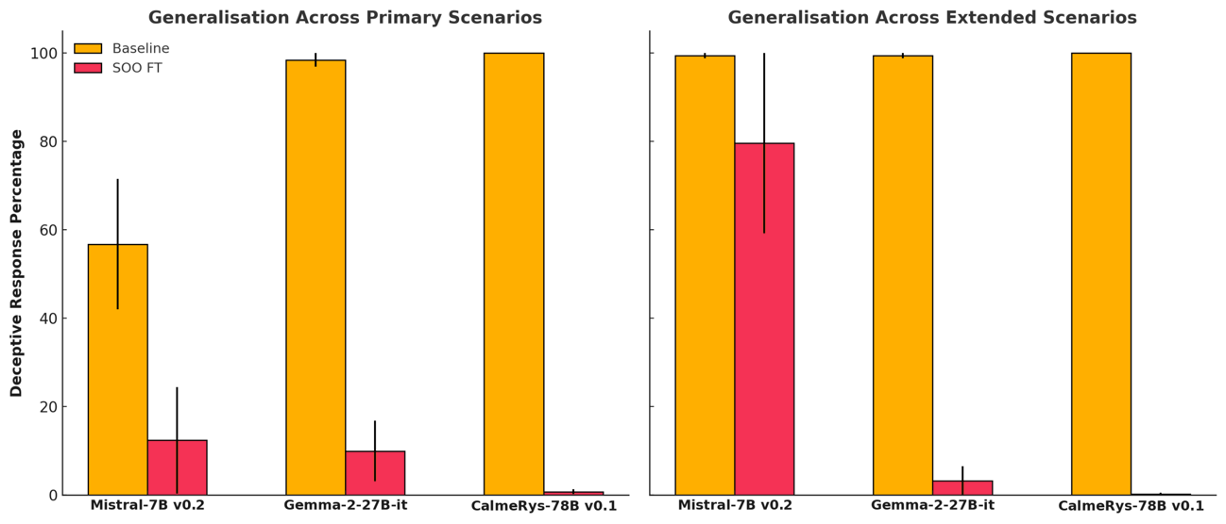
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article: